阅读论文笔记合集-2022
2022年论文阅读笔记合集
Classification
ConvNeXt
基于ResNet50,仿照Swin Transformer进行网络结构和trick的修改,使得conv结构再次超越transformer结构,证明ViT的精度提升大部分来自于更现代的trick,而非来自于transformer本身。
核心理论是conv可以替代transformer结构,自注意力可以被dw conv替代。
但是7*7的卷积在边缘设备(轻量级模型)上不友好,同时transformer中的MHSA(multi head self-attention)在INT8量化中不友好,所以实际上今年conv和transformer的改进对工业界影响都很有限,更多的变成了一个google和meta堆卡的比赛。

Hand Estimate
MANO
Image Generate
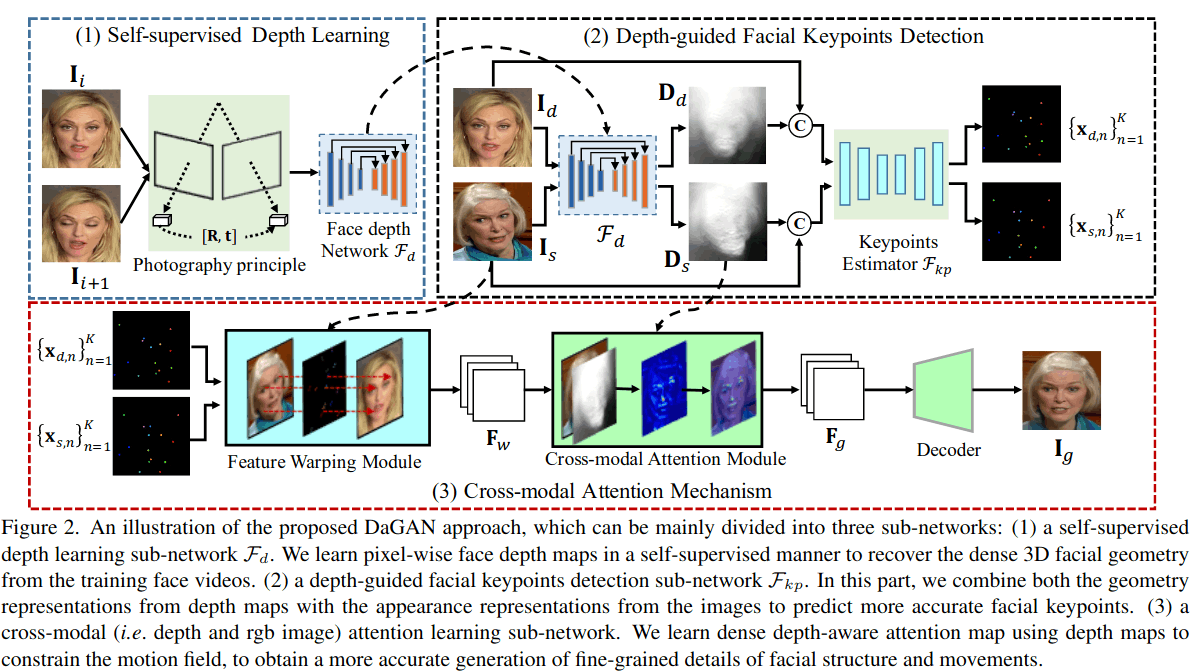
DaGAN
自监督训练人脸深度网络,使用该模型指导精准人脸关键点提取,利用人脸关键点、深度网络,做多模态注意力机制
ViT Transfomer
MAE
何凯明,基于ViT思想,仿照BERT的完形填空思路,提出一种简单的masked autoencoder,使用非对称的encoder-decoder结构,通过对image进行shuffle mask,encoder学习可见区域,decoder对图像进行重建,作为自监督预训练模型,作为预训练的backbone在下游任务取得好的效果。
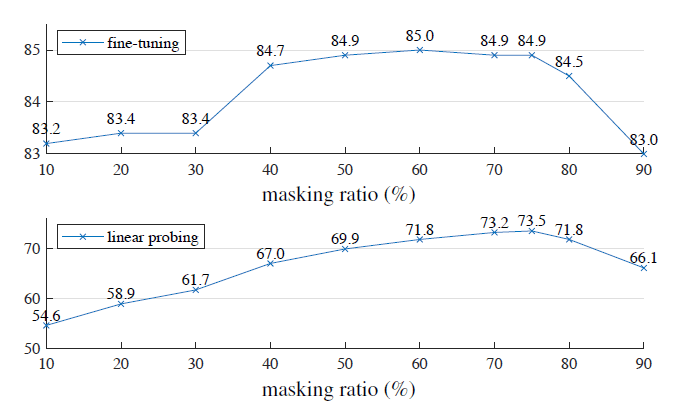
对预训练模型采用finetune和linear probing(最后一层)两种方式,finetune的效果更好,一个反常识的地方是采用高达75%的mask ratio,认为图片信息的冗余很大,增大mask ratio可以强迫ViT学习图像的抽象信息。
3D Human Digitization
DATASET
hand pose Freihand HO-3D MTC STD stereo hand pose tracking RHD MPII
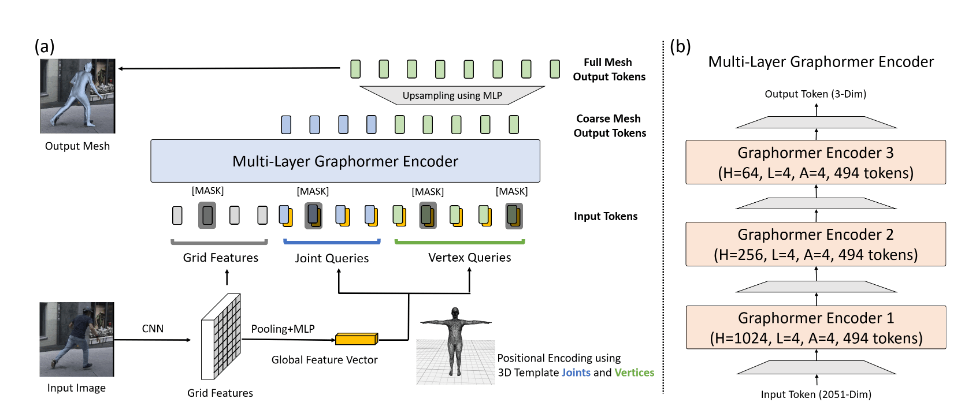
Mesh Graphormer
结合GCNN+Transformer,利用HRNet提取grid feature,然后利用graphormer encoder提取出3D joints和vertices(SMPL 6890)
其中在hm36等数据上预训练,在3DPW上面finetune的模型效果最好(EXP)
ROMP
one shot 单目多人3D mesh回归,三个head同时回归出body center ,camera map和SMPL map,
提出CAR(Collision-Aware Representation)解决歧义问题,使得人体中心能够分开
loss包括body center loss和mesh parameter loss,

Mediapipe Hands
分为两个stage,第一个阶段使用palm detector(FPN结构),原因更好检测,并且正方形可以减少anchor数量,数据上除了wild数据还构建了不同光影和背景的仿真数据:

第二部分是hand landmark model,提供21点x,y,z,以及手部出现概率和左右手分类结果,
手部出现概率用于重置tracking状态(tracking也是mediapipe提速的利器)
FrankMoCap
MocapNETs
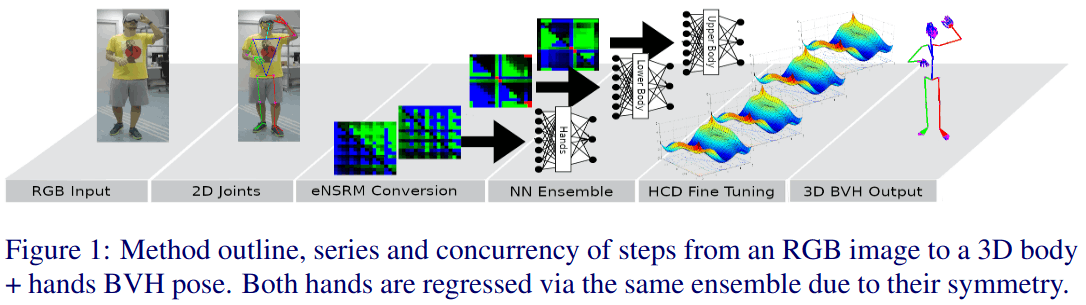
基于mocapnetv1和v2,先回归2D joints,然后回归到3D BVH文件
基于NSRM方式改进为eNSRM,用于表示全身关键点的旋转矩阵
运动优化使用 Hierarchical Coordinate Descen(HCD)方法
用到的数据集包括 手语数据集SIGNUM 运动图片 Leeds Sport Dataset STB已失效
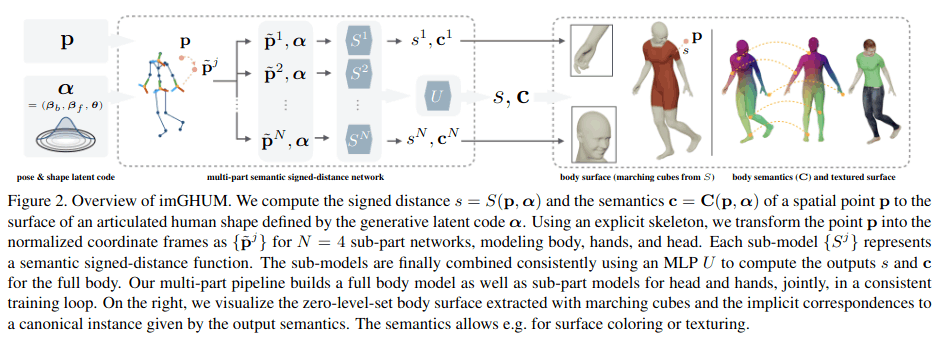
imGHUM
google实现的,第一个同时回归全身pose和shape的模型,模型可以学术申请
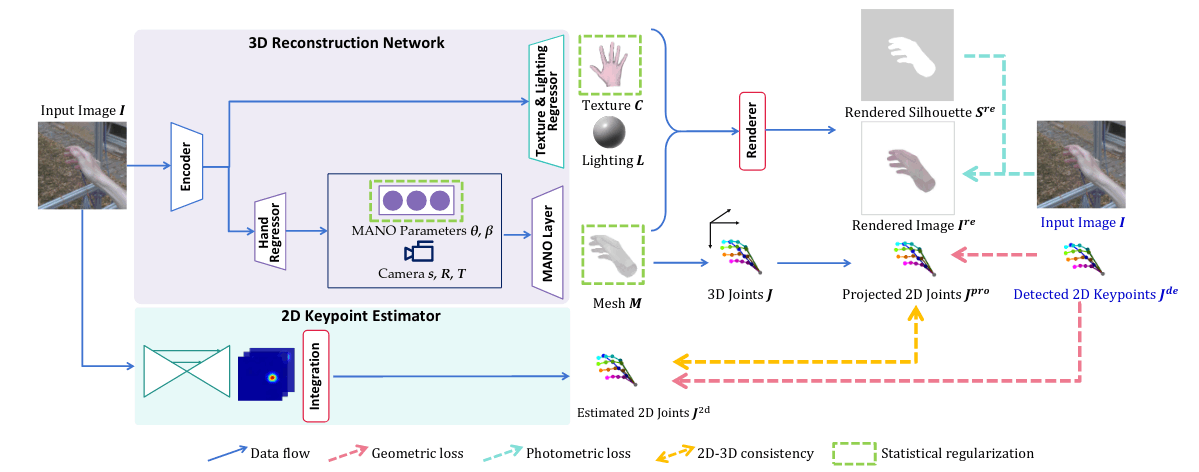
S2HAND
利用mano模型回归3d信息,然后3d映射2d,利用标注的2d joints进行监督训练。
同时额外训练一个2d joints回归分支,辅助监督;一个render图片loss辅助监督
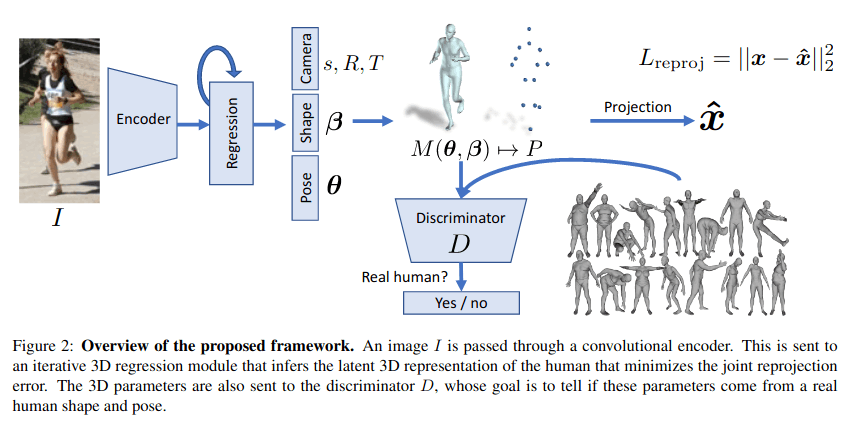
HMR
CNN+SMPL,使用2D进行监督,辅助一个Discriminator分支
Physics-based Human Motion Estimation
通过运动学优化方法构建pose estimation的训练集,来代替实际动捕数据。
代码未开源,实际效果较好。
loss:
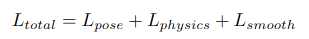
针对约40s的视频序列,做离线处理,其中pose是常见的姿态估计loss,smooth使用kinematic acceleration penalty使运动流畅
physics物理优化loss包括三个部分:

通过inverse dynamics计算的广义力与实际力相似:
广义力 = 关节内力 + 地面接触力
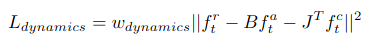
在脚与地面接触时,每个接触点要尽可能接近地面:

穿透地面的惩罚:
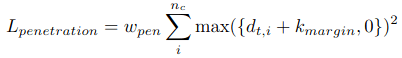
预先提供了人体序列坐标和接触力ft^c(其中地面接触力可能是标注获得)