阅读论文笔记合集-2021
2021年论文阅读笔记合集
Face Swap
FSGAN
paper:
https://arxiv.org/pdf/1908.05932.pdf
官方repo:
https://github.com/YuvalNirkin/fsgan
Disney高清换脸

InfoSwap
Information Bottleneck Disentanglement for Identity Swapping
codes: https://github.com/GGGHSL/InfoSwap-master
两点创新,一是 将IBA引入到arcface网络中:
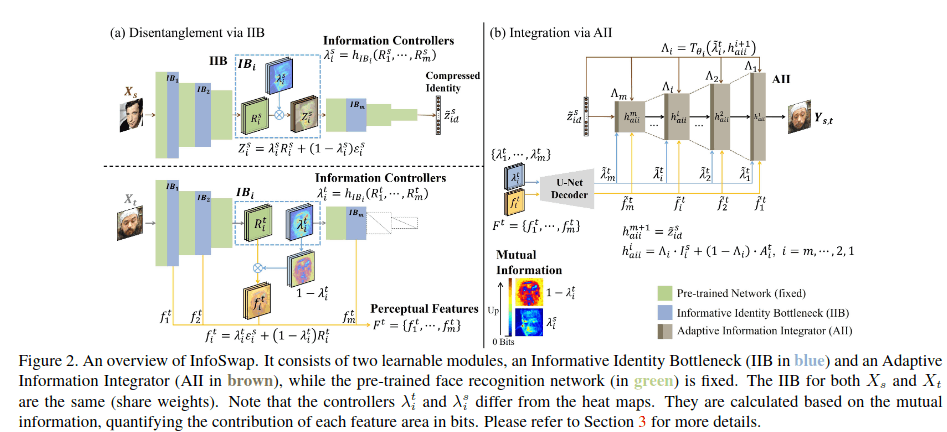
第二个是在计算IBA提取的feature loss的时候,不仅让output src cos距离最小,还让output target cos距离变大
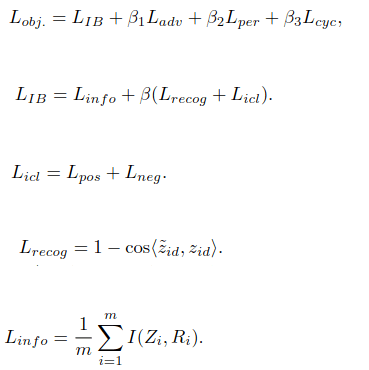
ShapeEditer
基于stylegan2,arcface提取id特征,pspnet提取attr特征,映射到latent,使用stylegan2生成图片
优点: 生成图片的分辨率达到1024*1024
缺点:不像
FaceShifter
SPatially-Adaptive (DE) normalization(SPADE)
adaptive embedding integration networ / AEI
adaptive attentional denormalization generator / AAD
参考AdaIN SPADE 利用denormalizion 在multi feature layer 做feature integration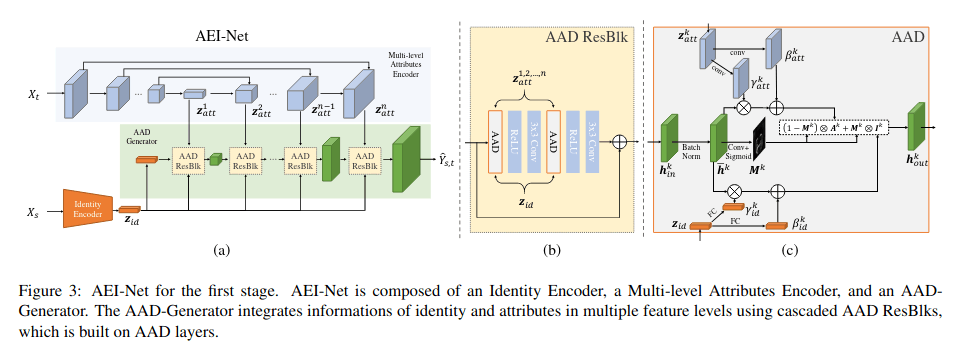
loss:
- reconstruction loss
- adversarial loss
- attribute loss (multi level)
- identity loss
HifiFace
复现效果可以,3D特征使用deep3dfacerecon,人脸特征使用curricularface, mask使用HRNet

预处理上,训练集VGGFace2,使用人脸特征+3D特征,其中3D特征使用其中的表情和动作,人脸特征使用
训练中,分为低分辨率和高分辨率两个分支,低分辨率使用1/4 feature size,方便身份和属性解耦,
同时SFF(semantic facial fusion module)会预测mask,解决遮挡和面部边缘融合问题
loss上,shape loss / id loss / segmentation loss / reconstruction loss / cycle loss / lpips loss
Super Resolution
PSNR SSIM ringing artifacts/sinc/ spectral normalization FID
ESRGAN & Real-ESRGAN
ESRGAN 整体基于SRGAN改进
RDDB结构,去掉residual block中的BN,使用dense block结构增加大量连接

Relativistic Discriminator 相对鉴别器
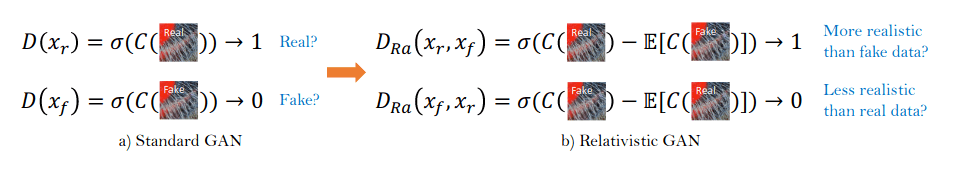
Perceptual Loss 感知损失,移到激活前,解决激活后特征稀疏导致的亮度问题
Network Interpolation 网络插值,先训练一个基于PSNR的模型,然后在GAN上finetune,二者结合
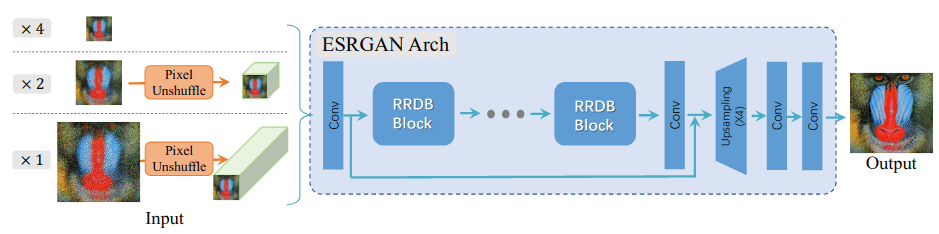
Real-ESRGAN 基于ESRGAN
通过2-stage的image degradation来构建训练集
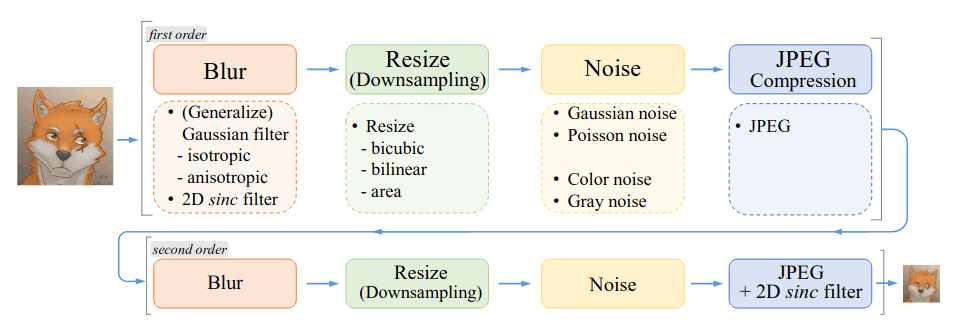
通过在first order和second order中加入sinc filter来模拟ringing artifact/overshoot 现象
pixel unshuffle操作,来解决1x 2x的放大问题
鉴别器替换为U-Net,加入spectral normalization ,使鉴别器满足1-Lipschitz条件,使生成器梯度不会消失
GFPGAN
出自腾讯,复现效果较真实
- 使用U-net构建一个degration removal模块,连接预训练StyleGAN2模型,分别使用latent和channal split SFT(Spatial Feature Transform)连接。
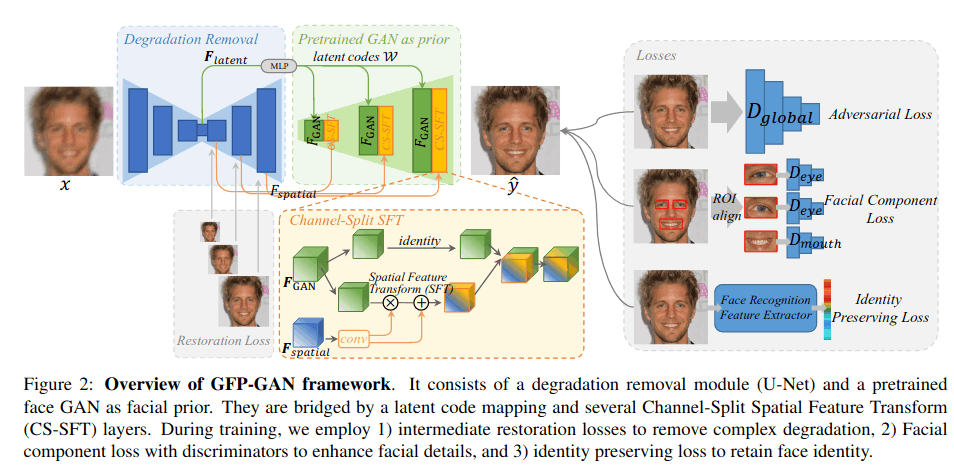
- 训练数据使用FFHQ做退化生成,测试集使用合成开源数据(应该加入了私有数据)
- 三个loss如图,加强了五官loss,增加identity loss
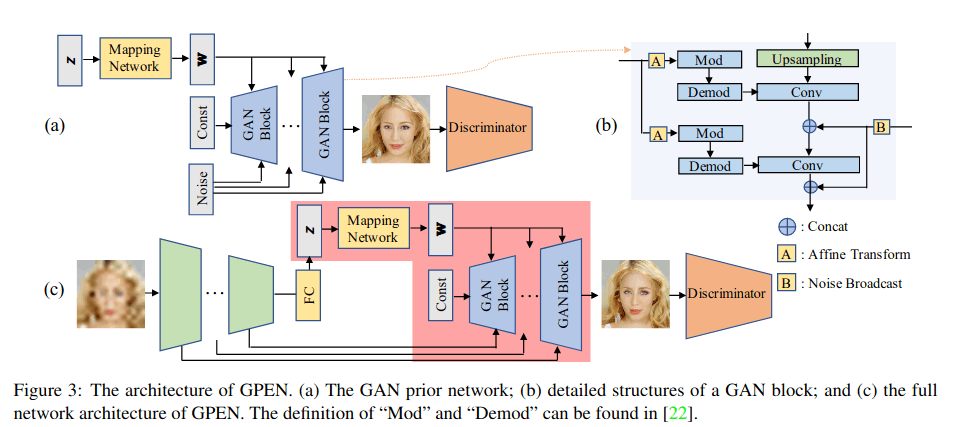
GPEN
出自阿里,定义BFR(blind face restoration)问题,复现效果色彩略微失真
先训练一个能生成高清人脸的GAN(FFHQ),然后把这个预训练的GAN嵌入到一个UNet结构中,作为它的解码器部分,这之后,整个网络再通过人工降质的数据对来进行微调训练。
在质量评估中使用了PSNR FID LPIPS
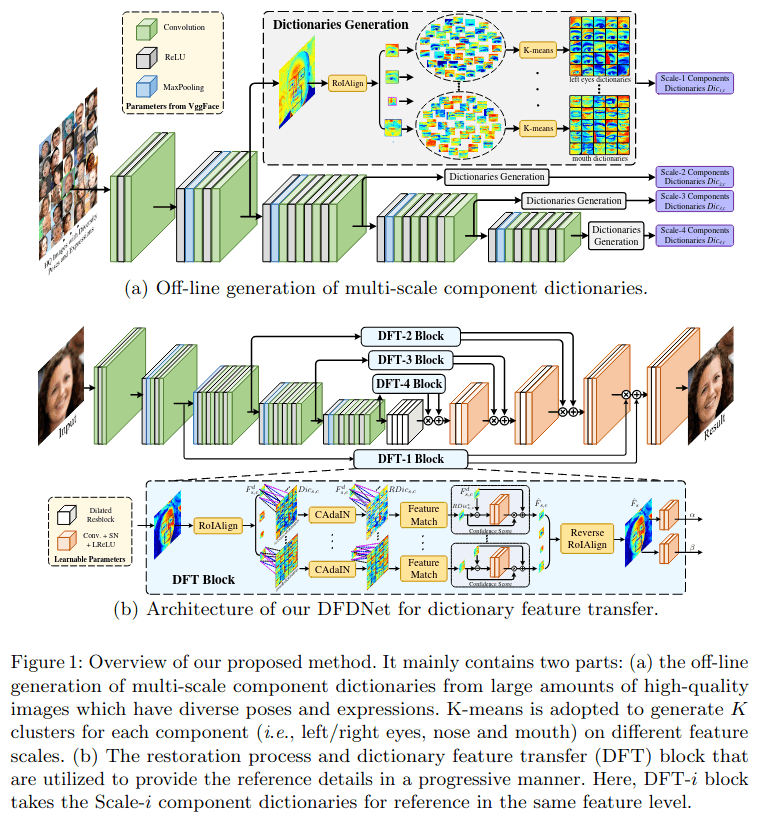
DFDNet
类似查找匹配,先用大量数据训练多尺度的component字典,然后使用这些字典训练DFT结构,中间提出CAdaIN(component AdaIN).
实测效果较好,但是生成痕迹明显,同时由于需要对五官做align,速度非常慢。
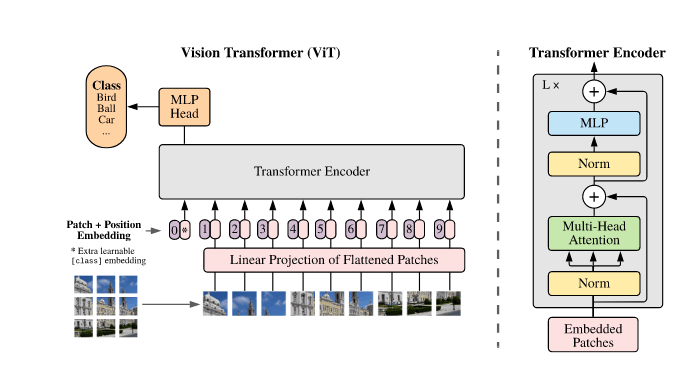
ViT Transformer
ViT
google brain.
ViT的基本思想: 将图片划分为固定尺寸patch,拉平后增加position embedding(代表位置信息),经过transfomer encoder和MLP head(Transfomer结构),
注意额外使用一个class token(learnable embedding )表示分类结果,避免对某个patch的偏重
优势: transfomer的跨模态能力,GPU友好,适合大规模计算,计算力上限高于CNN
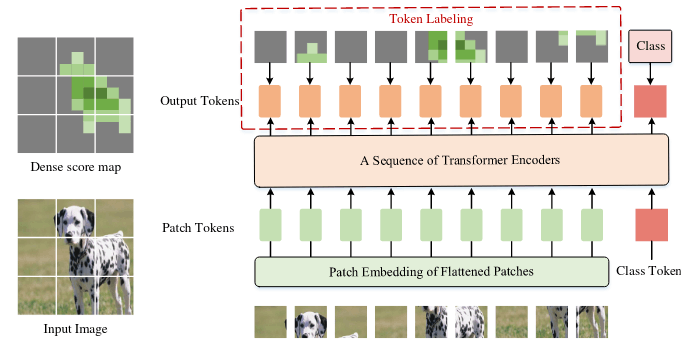
Token Labeling
起名LV-ViT,基于ViT,除了class对class token的监督以外,还引入了一个额外的score map对每个token进行监督,这个额外的source map来自另一个训练好的网络。
Tokens-to-Token ViT
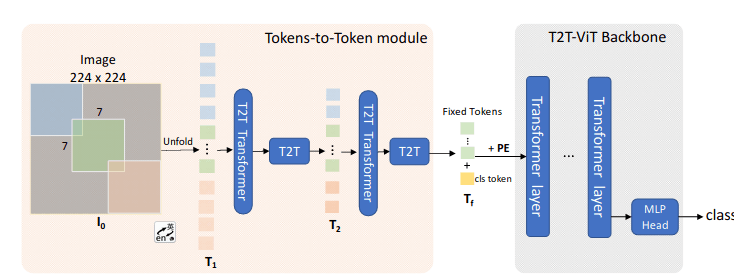
来自依图
基于ViT, 解决了ViT token长度一样和计算量大的问题, 思路是在ViT前面增加T2T结构,通过soft split + Unfold操作渐进式减少token的长度:
soft split: 在将图片切分成patch的时候,进行overlap,建立一个先验,即距离近的patch更相关
和ViT相比计算量下降明显,在Imagenet上面仍然能达到SOTA
在T2T结构的选择上,对比了五种结构,最终选择使用deep narrow的结构:
Dense connection as DenseNet [21];
Deep-narrow vs. shallow-wide structure as in Wide-ResNets [52];
Channel attention as Squeeze-an-Excitation (SE) Net-works [20];
More split heads in multi-head attention layer asResNeXt [44];
Ghost operations as GhostNet [14]
此外,T2T可以使用Performer代替Transformer以降低GPU占用 (Rethinking transformer based set prediction for object detection)
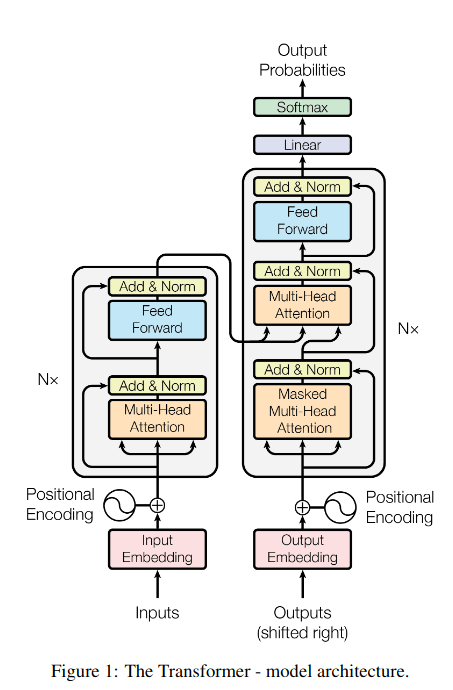
Attention is all you need
用于机器翻译,保持encoder-decoder结构,完全抛弃rnn和cnn,使用transformer架构
提出self-attention,包括query key value,由三个不同的权值矩阵得到
提出multi head attention,等于多个self-attention的ensemble
引入位置编码(position embedding)
3D Face Reconstruction
3DMM(3D morphable models )三维可变形人脸模型,每张脸表现为texture和shape的叠加,
基于传统方法model fit构建数据训练3DMM CNN,
3DDFA & 3DDFA_V2
3DDFA(3D Dense Face Alignment) 使用PNNC(Projected Normalized Coordinate Code) 作为特征预测,而PRNet使用UV
提出PAC(pose adaptive convolution),在语义一致性位置进行卷积
loss上分为参数距离(parameter distance cost)和顶点距离(vertex distance cost),一个最小化参数误差,一个最小化顶点距离,提高3DMM形变能力
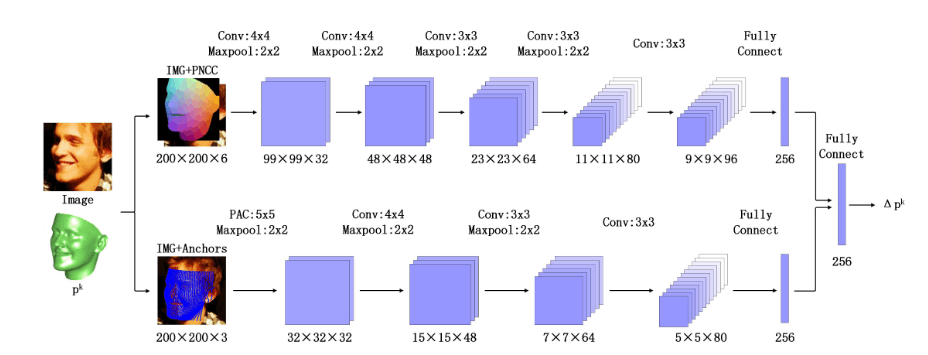
此外提出对训练数据大角度的增强,构建大姿态人脸库来训练模型
3DDFA_V2,针对3DDFA进行了提速,主要包括三点:
- landmark-regression regularization 加速拟合
- mata-joint optimization 动态组合loss,加速拟合
- 3d aided short-video-synthesis 使用静止图片生成短视频训练数据,提高video上的对齐效果

DECA
DECA模型分为粗糙的人脸重建Ec(resnet50构成),精细的人脸重建Ed。具体的Ec包括了相机c,反射率ɑ,光照l,形状β,姿态θ,表情Ψ。Ed包括了细节δ。
粗糙模型的损失包括了人脸关键点的损失 Llmk,眼睛闭合的损失 Leye,基于照片的损失 Lpho,ID损失 Lid,形状连续损失 Lsc,正则化损失 Lreg。
精细的人脸重建损失,包含了照片细节损失 LphoD, ID-MRF损失 Lmrf,软对称性损失 Lsym,细节正则化损失 LregD。
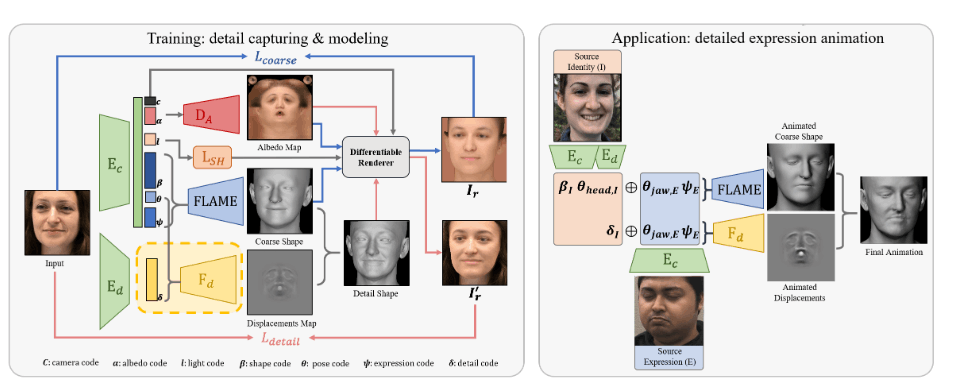
Deep3DFaceRecon
对R-Net提取的人脸相关系数进行重建,加入identity loss(arcface),引入光度损失(robust photometric loss)和关键点损失(landmark location loss),

Detailed3DFace
首先提供一个数据集
包含120G , TU models(938ID*20expression)和bilinear model
一个生成detail 3D face的demo,没有开源landmark检测器,代码中使用dlib替代
预测置换贴图(displacement map)使用pix2pixHD结构,使用dynamic details synthesis结合19个关键表情预测细节
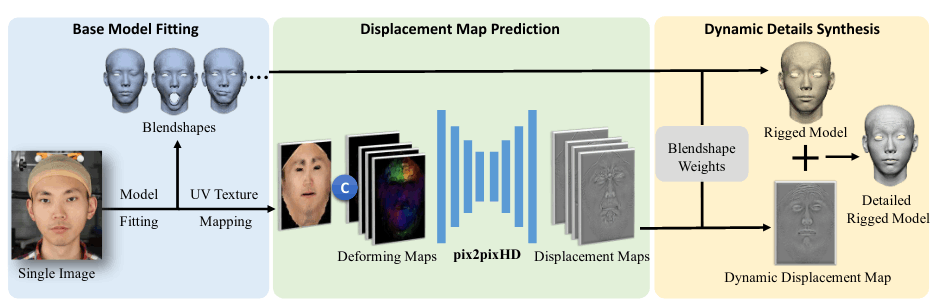
使用Detailed3DFace 可以获得:
一份半脸obj,一张UV贴图,一张对应的displacement map,20张其他表情的displacement map,和简单重建结果
使用zbrush重建结果:

帝国理工组
基础
3D模态(3D modalities) 包括 texture shape normals(法线) expression
帝国理工的LSFM https://github.com/menpo/lsfm , 中提到了MeIn3D数据集,包含10000张人脸,数据无法下载,参考https://github.com/menpo/lsfm/issues/27
CFHM Combining 3d morphable models: A large scale face-and-head model 2019 一种人脸和人头大规模模型
MICC 53个人头数据 http://www.micc.unifi.it/vim/3dfaces-dataset/index.html#!prettyPhoto
TBGAN
创新点: 提出一种trunk-branch architecture(主干分支结构),生成将texture和geometry耦合在一起的人脸
使用MeIn3D数据集, 将shape texture normals所有数据在UV平面对齐,以便输入GAN网络,增加一个表情识别网络,以操纵生成人脸的表情,基于CFHM将面部映射到头部

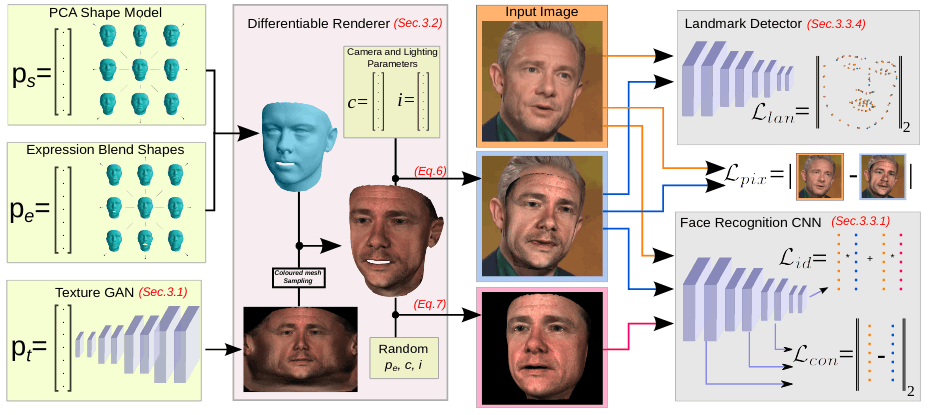
GANFit & Fast-GANFit
已经商业化,不会开源
其中ps和pe与3DMM一致,pt是由人脸latent提取UV map的网络,也就是shape使用3dmm,texture使用GAN生成,
加入一些loss保证GAN的生成质量,包括identity loss / content loss / pixel loss / landmark loss
最终结果使用MICC数据集评价
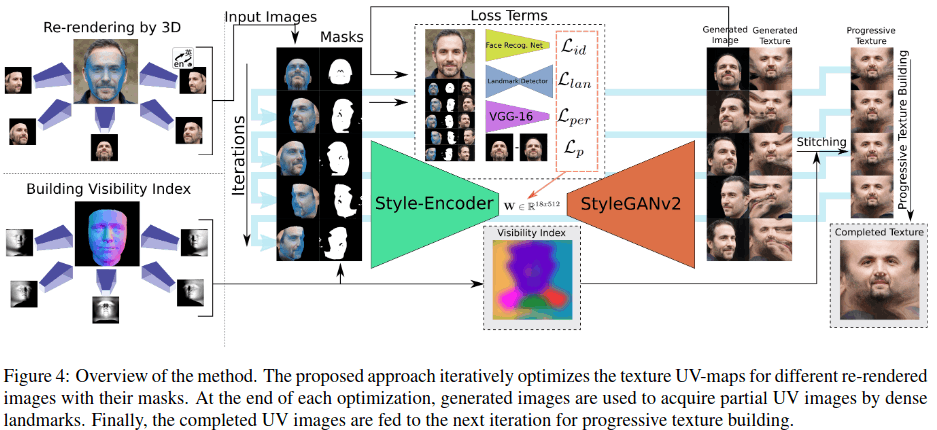
OSTeC
为了解决3d数据难以采集的问题,用2D生成器生成多角度的2D图片,然后构建3D数据集,用于训练3DMM
模型开源,需要申请
图片生成使用stylegan2,loss包括photometric loss(光度损失),identity loss, perceptual loss(感知损失), landmark loss, 渐进式生成纹理,最终stitching成一个UV map
能够达到GANFit的水平(10000张真实3d数据):
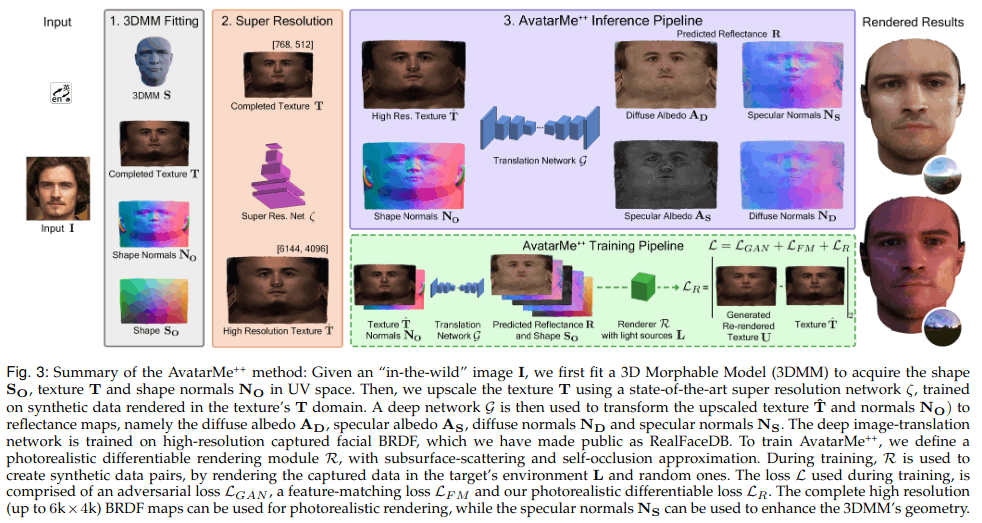
AvatarMe & AvatarMe++
用于实现 accurate facial skin diffuse and specular reflection, self-occlusion and subsurface scattering approximation (准确的面部皮肤漫反射和镜面反射、自遮挡和次表面散射近似)
先使用3dmm推理图片获得shape texture normals,然后进行超分获得高分辨率uv map,使用网络转换为4类漫反射 镜面反射 等贴图,进行光源渲染,然后计算loss
结果可以很好的使用任意图片进行3d重建,同时生成不同的光源渲染:
3D Human Digitization
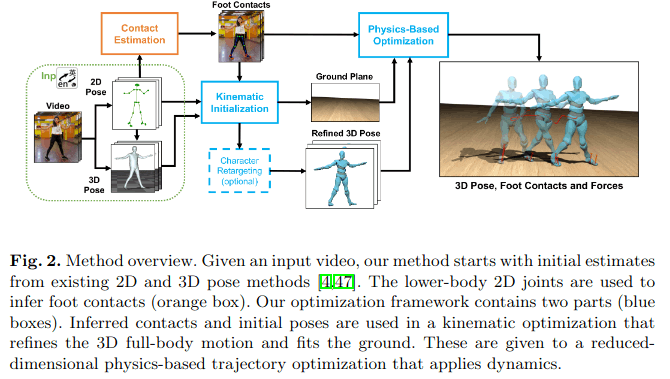
Contact Human Dynamics
基于openpose和MTC(Monocular Total Capture),分别提2D和3D pose,使用运动估计,对姿态和脚贴地有更好的支持。
其中运动学优化使用Towr
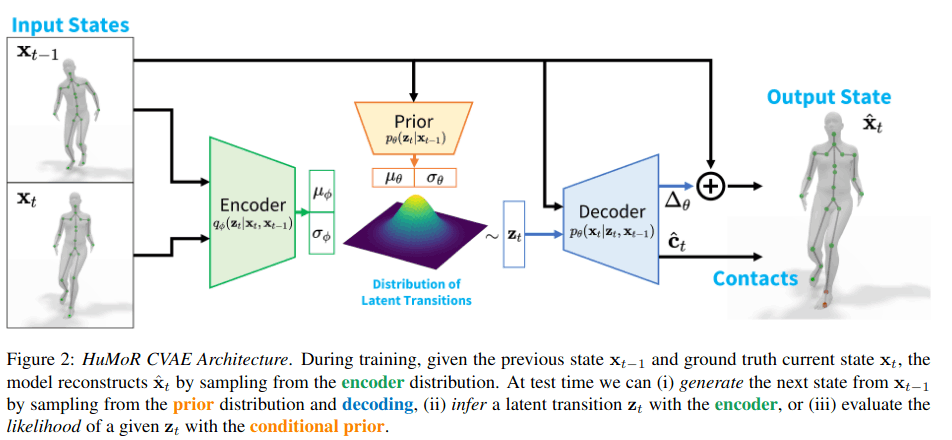
HuMoR
与contact human dynamics师出同门,第一篇contact human是用towr做运动学优化,第二篇humor提出了CVAE(conditional variational autoencoder)方法,是用编解码器去预测前后帧的运动学参数。
humor优化分 3 个阶段进行,第 1 和第 2 阶段是使用姿势先验和平滑(即 VPoser-t 基线)进行初始化,第 3 阶段是使用 HuMoR 运动先验进行全面优化。
DeepMotion
阅读deepmotion的API文档,发现提到poseEstimation.footLockingMode,很显然是对脚部锁定增加了额外选项
https://github.com/DeepMotion/Animate-3D-REST-API
参考deepmotion官网,deepmotion的运动学计算主要由motion brain完成,在英特尔宣传片中提到motion brain使用英特尔CPU加速技术进行优化,应该是运动学优化,和GPU无关
https://www.deepmotion.com/ai-motion-brain
https://www.youtube.com/watch?v=3acpP_WfqJY&t=32s
在deepmotion演示视频中看到pose estimation一样非常抖动
https://www.youtube.com/watch?v=Edia1conVAY
deepmotion也在做移动端适配工作,提到三步骤:constructs 3D human motion + physically simulates the result + retargets the motion to a desired character rig
Optimized for both speed and footprint on PC and mobile, our industry leading Body Tracking & Interaction SDK constructs 3D human motion, physically simulates the result, and retargets the motion to a desired character rig - all at run-time. Available for Windows, Linux, and mobile platforms.
https://www.deepmotion.com/3d-body-tracking
查阅发现UE4本身在17年就出现了foot locking插件
https://www.youtube.com/watch?v=uqsXmH4KBls
https://www.unrealengine.com/marketplace/en-US/product/advanced-locomotion-system-v1
使用locomotion做动画的实践
[https://thousun.github.io/2021/07/24/No.%20002%20Advanced%20locomotion%E6%8B%86%E8%A7%A3%E2%80%94P1.ABP/](https://thousun.github.io/2021/07/24/No. 002 Advanced locomotion拆解—P1.ABP/)
查看最新版本的animate 3D更新日志:
- Improved Ground Motions: Animation quality will see an improvement for ground motions that involve weight on hands, feet and other joints.
- Improved Ground Contact: General overall improved animation quality for limb ground contact and anti-tilting.
- Improved Tracking of Slower Movements: Real-time motions that are slower will see improved tracking.
通过对手 脚 关节重量的调整,优化了接地动作
提升身体各部分的接地质量
https://blog.deepmotion.com/2021/10/22/v34/
猜测deepmotion的离线处理主要由pose estimation + motion brain,motion brain的运动学优化与locomotion类似,需要大量cpu算力,并且无法做到实时
不排除在这个运动学优化的过程中,deepmotion增加了深度学习替代某些环节
最新推出的移动端应该进行了优化或者阉割,或者将某些计算步骤上云
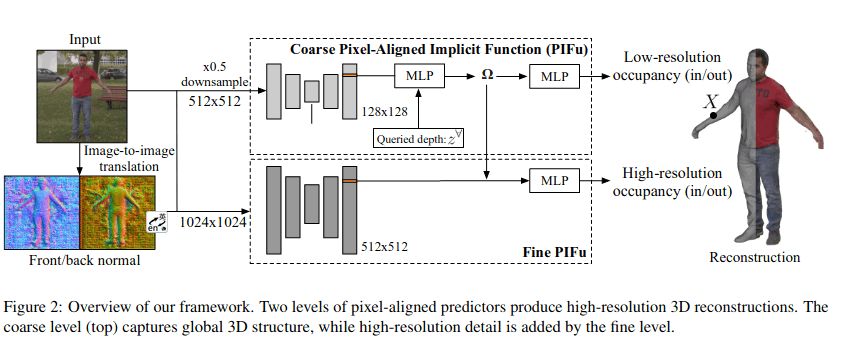
PIFuHD & MonoPort & NeuralBody
思路很好,但one-shot做人体3D重建,效果太差了。
- 之前的pifu最大输入尺寸限制到512512,pifuhd将输入尺寸提高到10241024
- 分为两个level,一个level是1024降采样到512,提取128分辨率的特征;另一个fine level,输入1024,提取512分辨率的特征